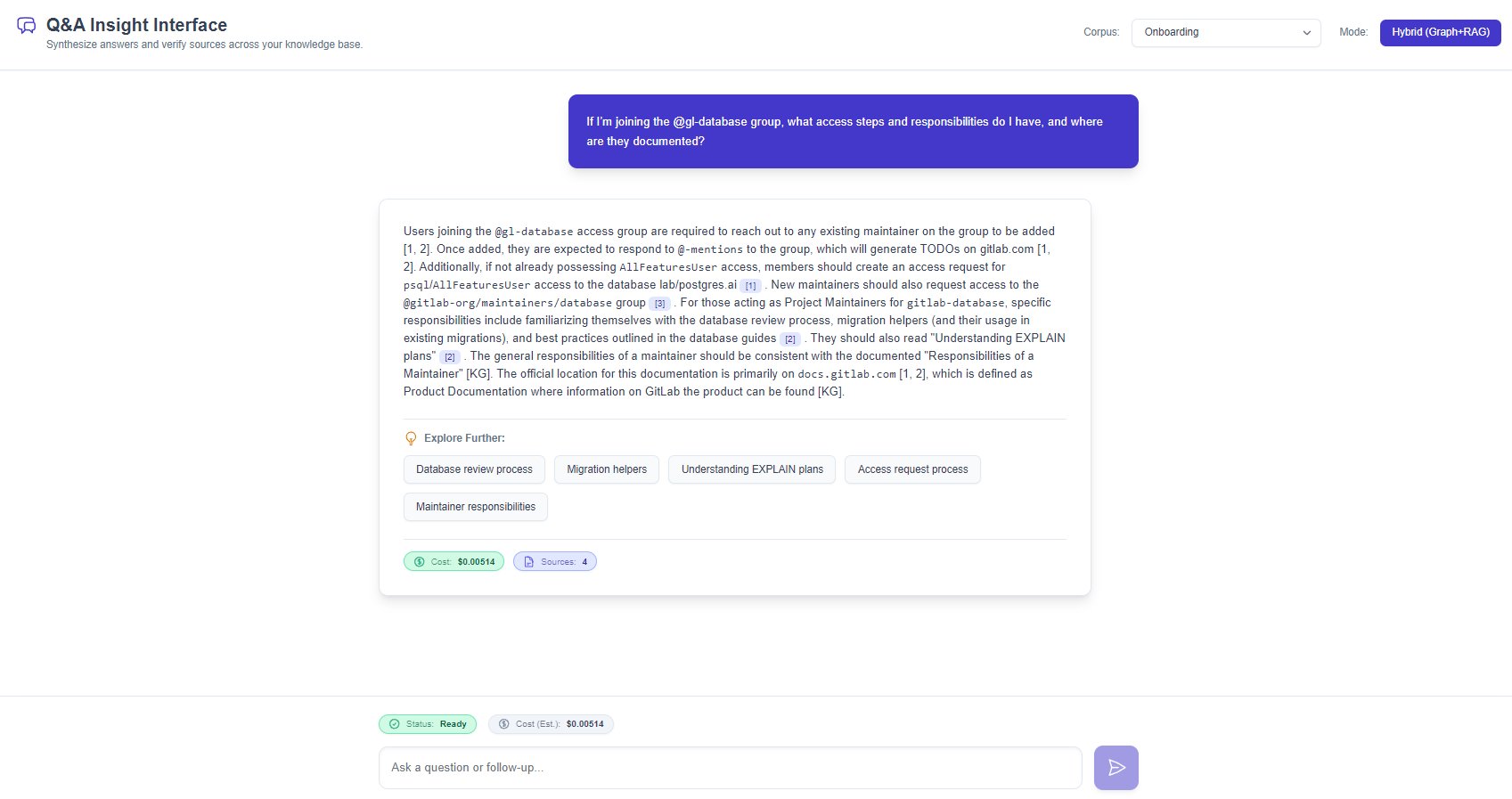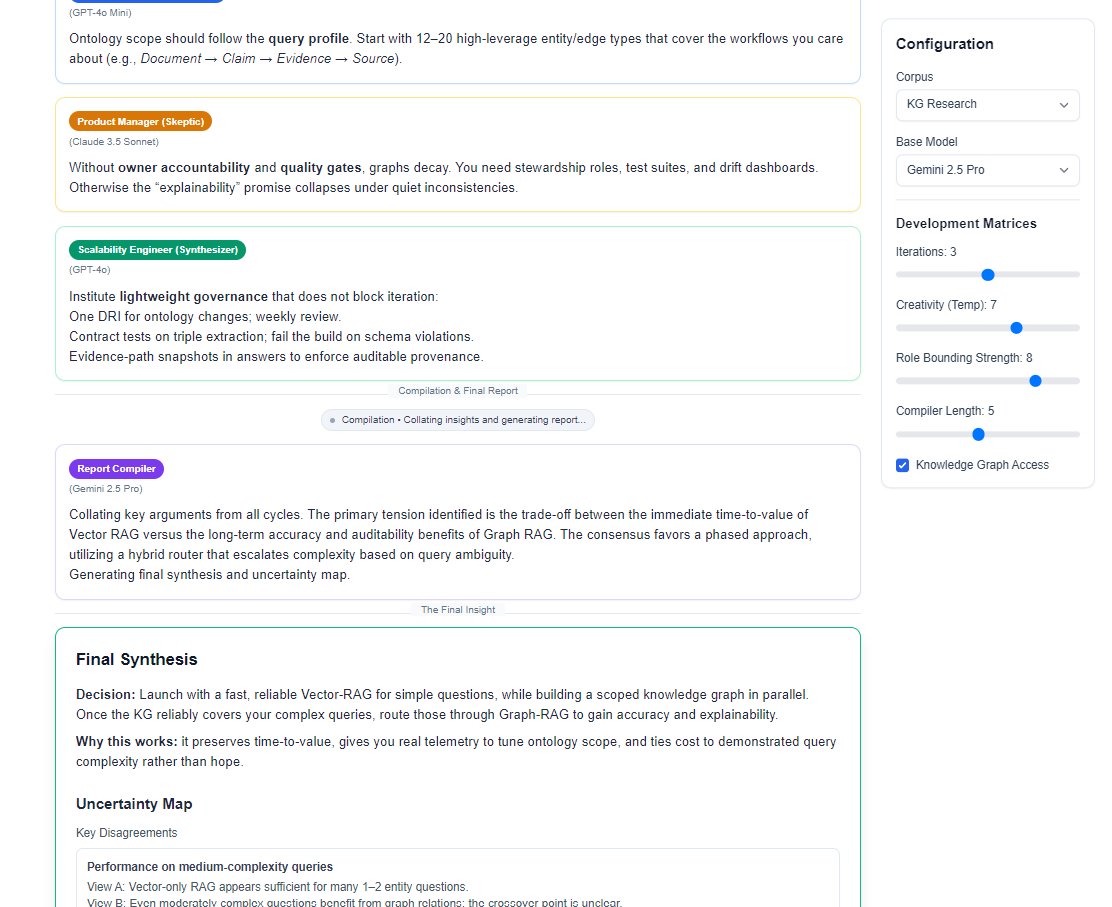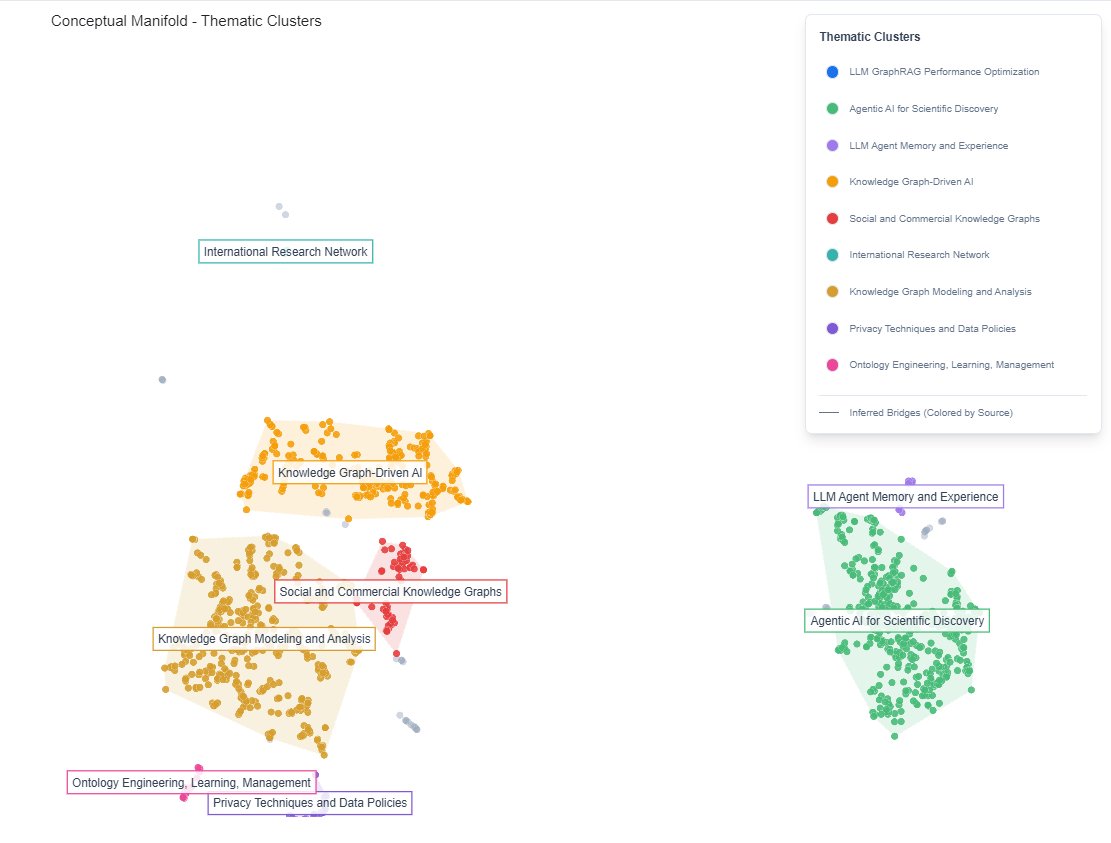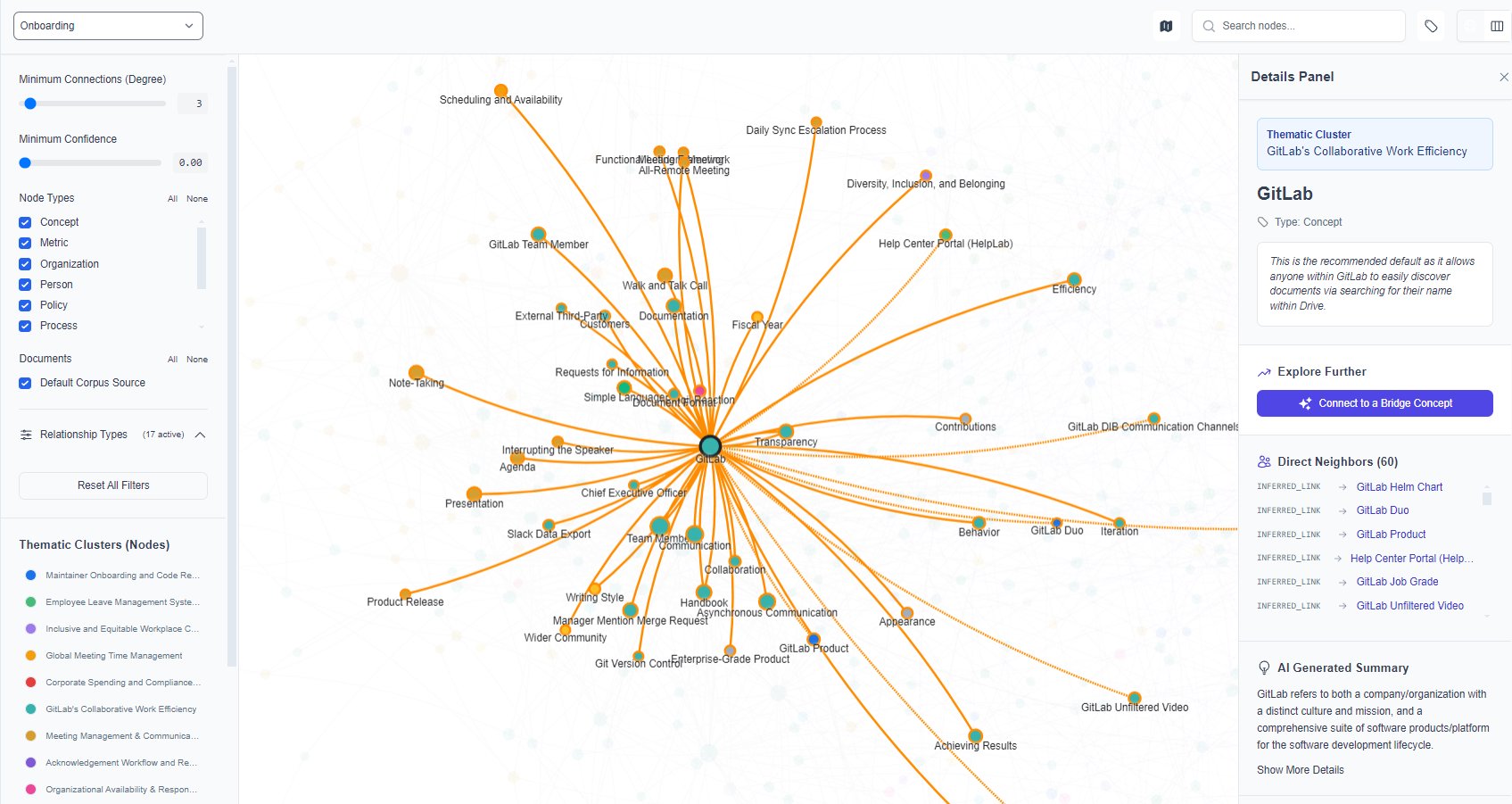
Figure iii · The Knowledge Graph Explorer with a GitLab-onboarding corpus loaded. Central node selected, 60 direct neighbours visualised, thematic clusters listed at left.
Interface 1 of 4 · Structural exploration
Knowledge Graph Explorer.
Interactive force-directed graph of concepts, documents, and inferred bridge edges. Filter by node type, relationship type, source document, confidence threshold, or minimum degree. Click a node to see its AI-generated summary and direct neighbours.
Heavy filtering computation runs in a Web Worker so the canvas stays responsive even at 100K+ nodes. Virtualization (react-window) handles search across the full node set. Thematic clusters in the sidebar come from UMAP projection plus agglomerative clustering, with cluster labels synthesized by the unification worker.